Docker Endeavor – Episode 2 – Liftoff

Table of contents
Review of episode 1
In episode one we wrote about the challenges we faced during the last two years of our Docker experiments. Some of the problems we found are still existing today but overall we get a Docker infrastructure up and running. This episode will cover how we do it.
Liftoff
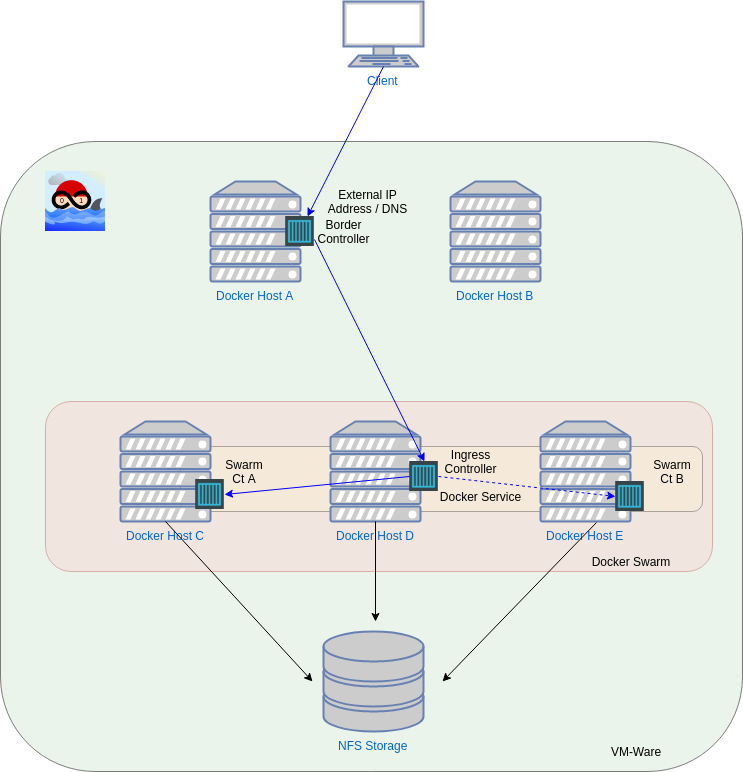
The blog-picture of this post, which you can see at the bottom, shows how we decided to setup our on-premise Docker infrastructure. In the following sections we explain the core components and we will also provide further information where, for example Github issues, are available. Explanation is structured from outside to inside - therefore VMWare is the first thing we will explain.
VMWare
As we started to build up our Docker environment we started with one single Docker host just to try out how far the Docker progress actually is. We decided to go with Ubuntu hosts because we already had Linux experience for a long time and therefore this seems a convenient way for us. Soon after the first tests the first questions came up. One of them was, how we should power the Docker environment as a whole infrastructure - should we install Docker (based on Ubuntu) bare metal or not? We read about it and we came to the conclusion, that installing Docker on bare metal is a bad idea because of some reasons.
- Bare metal operating system upgrades (not updates) are often a huge pain and the need to reinstall the whole system is common. That is really ugly if you have limited hardware resources. It is much easier to build up a new virtual Docker host and to startup the containers you need freshly on this Docker host.
- Other projects like Rancher prove that it is not unusual to run Docker in Docker to remove the operating system dependency and to build a cloud operating system like CoreOS or RancherOS (but that was too much for us).
- No, you don’t like hardware! As simple as this sentence is, hardware, networking, fiber channel connections, and so on are always a real challenge. Therefore a datacenter always needs a lot of persons who are doing this kind of tasks. To avoid this tasks, use a hypervisor of some kind. We have VMWare at work so we choose this one.
NFS-Storage
One single Docker host is easy to manage, it is like hacking 127.0.0.1. You can use Docker volumes, you can place the data on your local harddisk and all is pretty easy. But you will not be fail-safe. Therefore if you ever plan to use Docker in production you have to have more then one Docker host. And this is where the problems start. After we setup our second Docker host (now we have five) we quickly realized that we have to share data between hosts. Yes we know about data containers and so on, but this solutions are always limited in multi Docker host scenarios. A data container on Docker Host A is and will ever be on this host. If it fails it is gone. Kubernetes therefore provides Docker volume drivers which enables the containers to directly write to external storage, AWS, GCE,… but we are on-premise. OK, they also support NFS but managing Kubernete pod’s and Kube-proxy and other stuff is not easy. For this reason we decided to follow the KISS principle (Keep it simple & stupid) and we setup a central NFS server for our shared data.
As we write this we literally can look into the future and we will hear the people screaming in our comments: “Oh my god, NFS! They are using this f**** old crap piece of insecure software with this super-duper perfect Docker software!!!” - yeah, only three words on this… It just works.
The NFS share is organized in multiple sections. On the one hand every Docker host has its own area where host specific Docker container configuration files can reside. For example, this is useful if one of the Docker hosts is holding more than one ip address because some kind of “external ip address” is needed to provide a DNS entry with the correct information. In the bottom picture this is the reason why Docker host A is not in the Docker swarm. As you can see there, there is a container deployed who’s role is to be the border-controller. The border-controller will be explained in one of the following blog posts. On the other hand, the NFS share also covers an area where shared data is persisted, for example, if you have a MariaDB running in one of your containers (and logically only one container) then this container may be started on Docker hosts C-E in case of troubles because you deployed it as a Docker Swarm service. Therefore it is absolutely necessary to hold the data of the MariaDB container on a destination that is reachable from any possible Docker host.
Maybe there will be a better solution in the future to achieve this goal, but currently this is a valid setup.
Docker swarm
As you can see in the picture, we are using a Docker swarm setup. For example this is helpful for automatic deployments as a Docker stack service can be updated easily. The swarm makes it also possible to guarantee, that a service with a defined number of replica Containers is always running, regardless if there are only one or many Docker hosts. But currently you have to be careful because the Docker swarm is doing some things that you will not be aware of.
- Docker swarm does not support –net=host configuration. This means, that you will not be able to configure a needed network interface from inside a Docker container on a Docker host the container is running on. For example, an “external” ip address cannot move with the Docker container if the container is started on another Docker host. If you need such a setup, you cannot use Docker swarm at the moment. Now you now why in the picture at the bottom some Docker hosts are not part of the swarm - more information here -> #25873
- Docker swarm uses overlay networks between the Docker hosts, which is an impressive feature. But the Docker swarm mesh network does not support sticky sessions. This means, that a service published as Docker stack, will open up the exposed port on all Docker hosts of the Docker swarm. E.g. if you have five Docker hosts and you are running a Docker stack with a service that starts two Docker containers, then this two containers will be reachable through all five Docker hosts on the published port(s). Furthermore, if you start more Docker containers in a service as you have Docker hosts, e.g. ten Docker containers running on five Docker hosts, you will only have five input ways (trough the five Docker hosts) to the Docker containers. This mesh network will route the incoming traffic to a Docker container inside the Docker stack service randomly and you must not reach the same Docker container on the next request. Therefore some kind of ingress-controller is needed. That is why in the bottom picture a ingress-controller (Traefik based) is shown to manage these requests if stickiness is a must have. In most cases for us it is a must because in most cases the service running in the Docker swarm stack has no session database…
We know that a lot of people are saying “make stateless services” or “your applications have to use a session database” and so on, but this is not the reality of real live applications which have a long history. This is the point where theory (Docker) meets practice (real live). We will show you such an ingress-controller in one of the following posts.
Client
The client in this kind of setup can only connect to a DNS name, e.g. example.com. And of course the user on the client would like to only put in the domain name in the browser. A user will not an will never be comprehensive to learn ip ports like example.com:30001. Now you will say: “Meh, just publish the service on 80 and/or 443!”. Ouch, if you do this in a Docker stack service, port 80 and 443 are burned up on all Docker hosts! Starting only one service of this kind will render port 80 and 443 unavailable for any further services. This is why cloud companies like AWS, GCE, Azure and many more provide a service that is able to map a Docker swarm stack that is using a dynamic exposed port to an fixed ip address and which in turn is covered by a DNS server. This is the only way how it is possible to have many services with port 80⁄443 running in parallel. We call this service “border-controller” and now you know why!
But if you are on-premise there is no such service available. You are out of luck and if your users have to access a domain name as usual and if you would like to provide the service/application behind this domain name via the Docker environment, you have to setup a border-controller like you can see it in the bottom picture. But there are some pitfalls. For example, if you use Traefik as ingress-controller and as border-controller you will currently mess up the stickiness of your application -> #1574. We will show, how we managed this in one of the following posts.
Summary
This post contains a lot of information about many components of an on-premise Docker environment with Docker swarm stacks/services. Stay tuned, we will provide more insights soon. If you have any questions, don’t hesitate and leave a comment, you are welcome!
 Doing Linux since 2000 and containers since 2009. Like to hack new and interesting stuff. Containers, Python, DevOps, automation and so on. Interested in science and I like to read (if I found the time). My motto is "𝗜𝗺𝗮𝗴𝗶𝗻𝗮𝘁𝗶𝗼𝗻 𝗶𝘀 𝗺𝗼𝗿𝗲 𝗶𝗺𝗽𝗼𝗿𝘁𝗮𝗻𝘁 𝘁𝗵𝗮𝗻 𝗸𝗻𝗼𝘄𝗹𝗲𝗱𝗴𝗲. [Einstein]". Interesting contacts are always welcome - nice to meet you out there - if you like, do not hesitate and contact me!
Doing Linux since 2000 and containers since 2009. Like to hack new and interesting stuff. Containers, Python, DevOps, automation and so on. Interested in science and I like to read (if I found the time). My motto is "𝗜𝗺𝗮𝗴𝗶𝗻𝗮𝘁𝗶𝗼𝗻 𝗶𝘀 𝗺𝗼𝗿𝗲 𝗶𝗺𝗽𝗼𝗿𝘁𝗮𝗻𝘁 𝘁𝗵𝗮𝗻 𝗸𝗻𝗼𝘄𝗹𝗲𝗱𝗴𝗲. [Einstein]". Interesting contacts are always welcome - nice to meet you out there - if you like, do not hesitate and contact me!
 CloudArchitect/SysOpsEngineer; loves to get things ordered the right way: "A tidy house, a tidy mind."; configuration management fetishist; loving backups; impressed by docker; Always up to get in contact with interesting people - do not hesitate to write a comment or to contact me!
CloudArchitect/SysOpsEngineer; loves to get things ordered the right way: "A tidy house, a tidy mind."; configuration management fetishist; loving backups; impressed by docker; Always up to get in contact with interesting people - do not hesitate to write a comment or to contact me!
